We created the first microchips for deep learning — tensor processing units (TPUs). Our first silicon came back from foundry in 2011. The video above shows us opening up our first wafer from TSMC. Google’s first TPU project completed their first tape-out in silicon about 4 years later in 2015.
We developed the first processors for machine learning, providing huge efficiencies in Joules per Operation wins for deep learning (1,000x – 10,000x). On a range of image processing and signal processing benchmarks, we demonstrated 10x more operations per second (GOPS) and 100x lower power (Joules per operation) compared to the leading Nvidia GPU of the time. Compared to the leading CPU of the time (Intel Core i7) we demonstrated 100x more OPS and 10x lower Joules/operation.
Our architecture anticipated important features of today’s deep learning chips. Published patents include processor architecture1 2, enhanced data transfer specifically for moving model weights from memory3, factor/tensor operators4, the software framework for developing model architectures5, compiler for going from model to the processor6, and efficient methods for deciding which neurons to update7. We used the terms “factor” and “tensors” interchangeably8.
When we announced the analog version of these processors, it captured people’s imaginations and received a great deal of press coverage across major technology news outlets including being featured as the top story in the technology sections of both the in the New York Times9 and Wall Street Journal10. It was also covered in Wired11, MIT Technology Review12, Scientific American, The Register13, EE Times14, Reuters15, The Flash Memory Summit16, Phys Org17, MIT Press 18, PC World19, Chip Estimate20, and then was picked up and spread worldwide by many others such as KD Nuggets21 and The Bulletin22.
- We created a specialized compiler and programming language to take advantage of a deep learning processor, specialized for designing models and compiling them onto our chips. Dimple, “an open-source software tool for probabilistic modeling, inference, and learning” anticipated and helped provide a foundation for the creation of TensorFlow and PyTorch. It was used by Kevin Murphy’s team at Google to create the first version of Google Knowledge Graph.23
- We optimized how we accessed model weights from memory
Once you optimize the compute core of the tensor operations so that it is highly energy efficient, powering the wires that access memory dominates the energy consumption of processors. A significant source of data is the weights of the model. Unlike the data you are doing inference or training on, you know what these weights are in advance and during training you have numerous interesting ways to control how the weights are formed and are represented within a model.
We co-designed our compiler and our chip so that our chip could efficiently consume the model weights, and leverage both graph sparsity and weight sparsity (skipping weights that are zero).
We also took advantage of the fact that groups of weights would be accessed in an orderly way as computations progressed through the deep learning model.
Modern chips like Amazon’s Inferentia chips do a subset of what we did. They allow, for example, 2 out of every 4 weights to be discarded before performing any computation with them, saving energy and silicon. Methods for further sparisfying networks is an intense area of research24. Our chip anticipated increasing sparsity. Our scheme for indexing and computing on particular activations or weights in the network enabled the compiler to cherry-pick a highly sparse subset to load into the processor. This approach could become increasingly attractive as network sparsity continues to increase. - We created the first on-chip weight quantization. In 2009 – 2012, when Hinton et. al. were first experimenting with quantization of neural weights, we had already run massive simulation studies ($300,000 cloud simulations seemed extreme at the time) to determine the minimum number of bits needed to represent weights and activations. We learned that these values could always be represented by very compact 7-bit fixed-point numbers or by combining even smaller mantissa with a small exponent. We also learned that we could perform rescaling for an entire layer of logits to keep all of the values in a tensor within a tight numerical range, and we took advantage of this in our design. Modern AI processors rely heavily on this approach.
I was the Founder, Chief Scientist, and CEO of Lyric Semiconductor, Inc. which grew out of my PhD work at MIT and Mitsubishi Electric Research Labs (MERL) in Cambridge, MA. Our small team comprised a little over 20 people people including David Reynolds, Jeff Bernstein, Bill Bradley, and Theo Weber.
Our startup was acquired by ADI, the largest analog/mixed-signal semiconductor company in the US, and became the new machine learning/AI chip group. Our team’s innovations were incorporated into wireless infrastructure, medical devices, self-driving cars, mobile devices, and other applications.
I gave a Google Tech Talk on July 9, 2013 presenting our benchmark results. This was the outline of the talk. I focused the talk on ML/AI applications that would have value within Android phones, including gesture recognition, speech recognition, and wireless receivers:

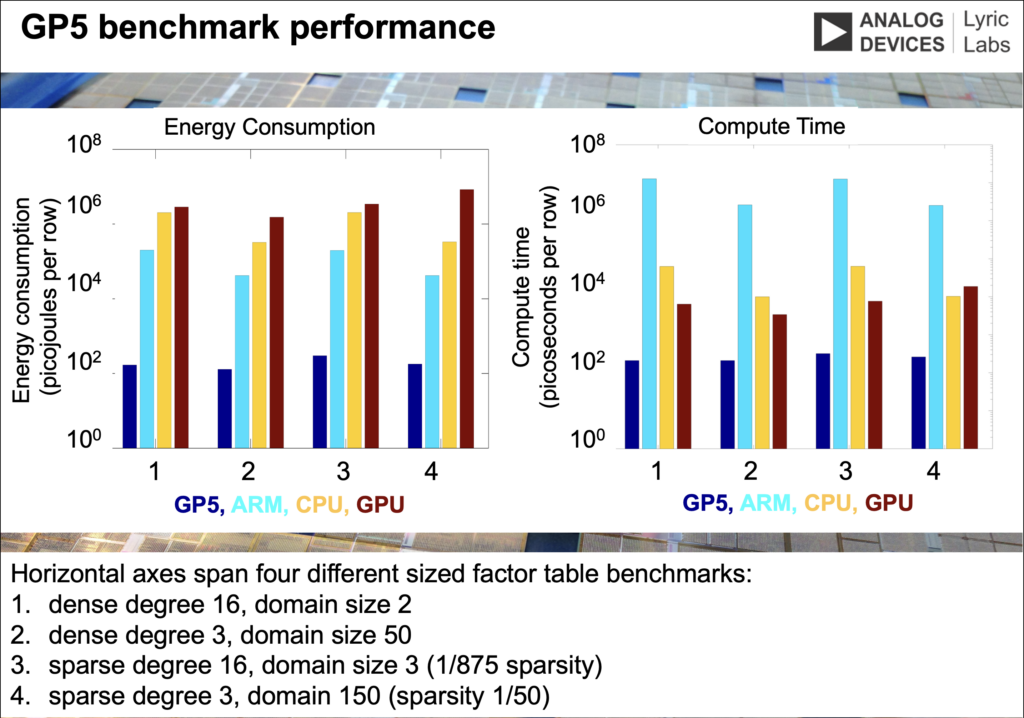
I presented the benchmark results in the slide below:
- Compared to the best NVidia GPU of the time (GeForce GTX 780), our processor (GP5) consumed better than 1,000x less power while also providing an output in better than 10x less time.
- Compared to the best CPUs of the time (Intel Core i7), GP5 consumed better than 100x less power and provided an output 10-100x faster.
- Compared to ARM cores which are designed for low power in mobile devices, GP5 consumed better than 100x less power, and provided an output better than 1,000x faster.
We called our processor the General-Purpose Programmable Parallel Probability Processor (GP5).
The “tensor” in a Tensor Processing Unit (TPU), refers to the structure of the deep learning model and the structure of the operations that need to be performed. The words “tensor” in mathematics and “factor” in connectionist deep learning models were used interchangeably at the time. Google’s tensor processing units (TPUs) and our Probability Processors perform multiplies, adds, and other operations on logits. A semi-ring defines the algebraic structure of the tensor contractions (matrix multiplies, convolutions) that are executed.8
We called our chip a General-Purpose Programmable Parallel Probability Processor (GP5), referring to tensors only internally. We even had an analog version of the same processor where the logits were represented by analog electrical currents.
Pulling together all of the innovations in these chips, we saw approximately four orders of magnitude in power savings compared to state-of-the-art GPUs of the time.
- Programmable Probability Processing, Bernstein, Jeffrey and Vigoda, Benjamin, Analog Devices, Inc., US Patent 9,626,624 B2, issued April 18, 2017. ↩︎
- Belief Propagation Processor (PDF), Reynolds, David and Vigoda, Benjamin, Mitsubishi Electric Research Laboratories / Analog Devices, Inc., US Patent 8,799,346 B2, issued August 5, 2014. ↩︎
- Belief Propagation Processor, Reynolds, David and Vigoda, Benjamin, Mitsubishi Electric Research Laboratories / Analog Devices, Inc., US Patent 8,799,346 B2, issued August 5, 2014. ↩︎
- Belief Propagation Processor, Reynolds, David and Vigoda, Benjamin, Mitsubishi Electric Research Laboratories / Analog Devices, Inc., US Patent 8,799,346 B2, issued August 5, 2014. ↩︎
- Implementation of Factor Graphs, Hershey, Shawn and Vigoda, Benjamin, Lyric Semiconductor, Inc. / Analog Devices, Inc., US Patent Application 20120159408 A1, published June 21, 2012. ↩︎
- Analog Computation Using Numerical Representations with Uncertainty, Vigoda, Benjamin and Bradley, William and Hershey, Shawn and Bernstein, Jeffrey, Lyric Semiconductor, Inc. / Analog Devices, Inc., US Patent 8,458,114 B2, issued June 4, 2013. ↩︎
- Superscalar Control for a Probability Computer, Vigoda, Benjamin, WIPO (PCT), WO2011103587 A2, published August 25, 2011. ↩︎
- In a factor graph computing belief propagation, we could have, for example, a softAND gate with incident edges A, B, C. Logically, C = AND(A,B), which yields the tensor or “factor” computation p_C = \sum_{A,B,C} \delta(C-AND(A,B)) p_A p_B.
Accelerating Inference: Towards a Full Language, Compiler and Hardware Stack, Hershey, Shawn and Bernstein, Jeffrey and Bradley, Bill and Schweitzer, Andrew and Stein, Noah and Weber, Théophane and Vigoda, Benjamin, NIPS Workshop on Probabilistic Programming, December 2012. ↩︎ - A Chip That Digests Data and Calculates the Odds, Ashlee Vance, New York Times, August 17, 2010. https://www.nytimes.com/2010/08/18/technology/18chip.html ↩︎
- Lyric’s Chips Probably Interest Spooks, Shoppers, Don Clark, Wall Street Journal, August 17, 2010. https://www.wsj.com/articles/BL-DGB-17239 ↩︎ ↩︎
- Probabilistic Chip Promises Better Flash Memory, Spam Filtering, Wired, August 17, 2010. ↩︎
- A New Kind of Microchip, Tom Simonite, MITTechnology Review, August 17, 2010. https://www.technologyreview.com/2010/08/17/90614/a-new-kind-of-microchip/ ↩︎
- DARPA Funds Mr Spock on a Chip, The Register, August 17, 2010. ↩︎
- Chip Odyssey 2006: The Start of the Modern Chip Era, Weckel, Alan, EE Times, October 29, 2024. ↩︎
- The Odds Are Good That Lyric Semiconductor Will Change Computing, Reuters, August 2010. ↩︎
- LDPC Error Correction Using Probability Processing Circuits, Vigoda, Benjamin, Flash Memory Summit, Session 201, August 19, 2010. ↩︎
- Computer Chip That Computes Probabilities and Not Logic, Phys.org, August 19, 2010. ↩︎
- High Probability of Success, MIT News, Massachusetts Institute of Technology, May 1, 2013. ↩︎
- Chip Startup Developing Probability Processor, PCWorld (IDG Communications), August 18, 2010. ↩︎
- MIT Spin-Out Lyric Semiconductor Launches a New Kind of Computing With Probability Processing Circuits, ChipEstimate, August 2010. ↩︎
- A Chip That Digests Data and Calculates the Odds, Vance, Ashlee, New York Times (via KDnuggets), August 17, 2010. ↩︎
- A Chip That Calculates the Odds, Vance, Ashlee, The Bulletin (via New York Times), August 18, 2010. ↩︎
- Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion, Dong, Xin and Gabrilovich, Evgeniy and Heitz, Geremy and Horn, Wilko and Lao, Ni and Murphy, Kevin and Strohmann, Thomas and Sun, Shaohua and Zhang, Wei, Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2014, pp. 601–610. ↩︎
- Frankle, J. & Carbin, M. The lottery ticket hypothesis: finding sparse, trainable neural networks. In International Conference on Learning Representations (2018). ↩︎
- In a factor graph computing belief propagation, we could have, for example, a softAND gate with incident edges A, B, C. Logically, C = AND(A,B), which yields the tensor or “factor” computation p_C = \sum_{A,B,C} \delta(C-AND(A,B)) p_A p_B.
Accelerating Inference: Towards a Full Language, Compiler and Hardware Stack, Hershey, Shawn and Bernstein, Jeffrey and Bradley, Bill and Schweitzer, Andrew and Stein, Noah and Weber, Théophane and Vigoda, Benjamin, NIPS Workshop on Probabilistic Programming, December 2012. ↩︎