By Ben Vigoda and Thomas Rochais
with special thanks to Erik Strand, Neil Gershenfeld, and Matt Barr
Inductive Transformers offer the opportunity to design artificial intelligence in addition to training it. The potential outcomes include:
- Orders of magnitude improvement in training data efficiency
- Continuous learning from each new data point
- Asymptotically unlimited context window
- Learning results in localized concepts that are interpretable and editable
- Enhanced long-range planning and reasoning
These outcomes present both powerful benefits as well as risks.
Deer babies learn to walk within ten minutes of being born. By comparison, human babies take a year to learn to walk – humans learn to walk 50,000x slower than deer! Said another way, when they’re born, deer baby brains know 50,000x more about how to use their legs than human babies do.
Human parents could perhaps be jealous of deer for learning so fast. If so, AI parents should be just as jealous of humans. Humans learn to talk and think after experiencing a few hundred million words — hearing, saying, reading, writing, thinking, dreaming.1 By contrast, an AI “baby” requires on the order of ten trillion words.2 Human babies know roughly 50,000x more about talking compared to AIs.3
And this learning gap doesn’t just apply to babies. Here in 2026, no AI has reached PhD level autonomy yet.4 They can be impressive when you talk with them, but they fall apart when you leave them on their own for a while to talk to themselves about their own research project. 5 To achieve PhD-level or professor-level, frontier models plan to increase their training data to roughly 1,000 trillion words. The lifetime experience of a human professor is on the order of a billion words.6 This would expand the efficiency gap between AI learning and human learning to approximately 1,000,000x. If the trend continues, this gap will further widen at the Nobel prize level.7

What if AI could learn as efficiently as humans? For one thing, data centers for training AIs today would get a lot smaller. If AI could be trained with 50,000x less data, that would take a one million square foot data center for AI training (several coming online in 2026-2027) and reduce it to the size of a closet. It would also take the ~1 Gigawatt power plant that powers such a data center (electricity for a third of Manhattan), and reduce it to the electricity used by about 13 hair dryers.8
How do humans achieve this much learning efficiency? The short answer is that while an AI is nurtured on language data after being initialized (“born”), humans have language learning designed into our nature by evolution before we are born. There’s a lot to unpack about how that works.
Learning to Walk

Let’s start with learning to walk, before we tackle learning to talk. There are only two ways for a human or deer baby to learn to walk. It can either wiggle its legs around to learn, or inherit the knowledge from its ancestors.9 Evolution has designed deer so they are born with a nervous system that is already tuned for the “spring-loaded pendulums” that are deer legs. That’s why they learn to walk faster than humans.10
So what could evolution be providing to human babies to help them learn to talk and think? Usually when people think of providing a prior to an AI, they think of programming in specific details. At the risk of stating the obvious, specific prior knowledge about dolphins and lollipops is not encoded into our DNA.11
Learning to Talk

Similar to the deer learning to walk, our prior for talking may have begun as a faculty for sequencing physical actions. Take, for example, making a bow and arrow. To make an arrow, first you gather and smooth a straight stick, then you find and sharpen a hard rock, and then twist and tie a string to bind them. But to assemble these components you need something in addition to string — you need a working plan. That same plan also lets you keep in mind that after you finish one arrow you will make more arrows and also a bow. Making complex artifacts requires a logical hierarchy of sequences — a bow and arrow is evidence of grammatical thinking, fossilized in wood and stone.12
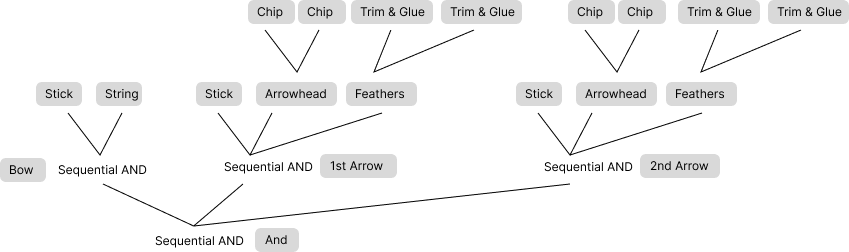
Story Time

Now let’s look at a simple example of language and thought — the children’s story, Goldilocks and the Three Bears. In the Goldilocks story, we can notice the same kinds of hierarchical logical sequences that we saw in the “story” of how to make a bow and arrows. The story of Goldilocks involves nested sequences of actions and so does the plan for making a bow and arrow.13
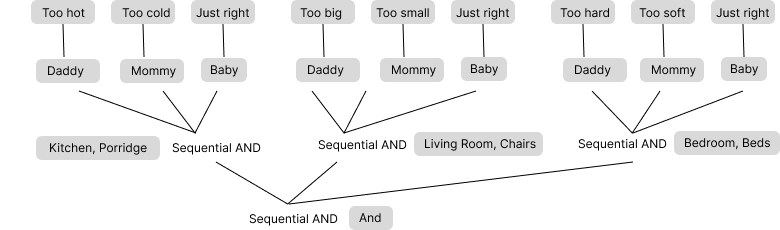
Goldilocks goes into the kitchen and tastes each of the three bowls of porridge. (First we make a bow by preparing the stick, preparing the string, and attaching them together). Then she goes into the living room and tries each of the three chairs. (Then we make the first arrow, starting with the stick, adding the arrowhead, and then the feathers). Finally Goldilocks goes into the bedroom to try each of the three beds. (Then we make a second arrow, re-using the same sequence.)
Hierarchical logical sequences appear everywhere humans think
As a story, Goldilocks is pretty strange, actually. Nothing really happens! The bears come home and they sequentially retrace goldilocks steps, noticing each item in sequence just as she did. Ultimately she runs away… What is the moral of this story? Why do we tell this story to our kids? There doesn’t seem to be a reason.
Interestingly, there are very similarly structured children’s stories in folklore across a great number of cultures.14,15 One hypothesis is that these kinds of children’s stories help to reinforce for children how to organize their thoughts into logically nested sequences. These structures are not just satisfying for children, and not just limited to words; the sonata form uses logically nested triples made into music, and much other great music is highly grammatical.16
Hierarchical logical sequences appear everywhere humans think — in toolmaking, in children’s stories across unrelated cultures, and in musical form. This is an inherited structural prior that humans have and today’s AIs do not, and that we would argue radically enhances human long-range planning and reasoning.
Our goal was to design AI with a propensity17 for learning logically nested sequences like Goldilocks and Three Bears rather than arbitrary patterns. We do this without programming any specific information about girls, porridge, or magical bears.
The actual math is fairly complex, but in essence we start with an ordinary attention transformer and add extra constraints (a.k.a. Lagrangians18) to constrain the model’s learning.19 20 We call such an AI model an “inductive transformer.” Let’s see how this speeds up language learning:
A “Vanilla” Language Model Learns to Talk
We’ll start with impressively miniscule training data — just 54 sentences:
The training data
In the kitchen , goldilocks initially tasted mama bear’s porridge ; it was too cold. Within the kitchen , she quickly sampled mother bear’s oatmeal ; it was very chilly. Inside the kitchen , goldilocks rapidly sipped momma bear’s soup ; it was really frigid. Visiting the kitchen , she initially nibbled mama bear’s stew ; it was extremely cold. Entering the kitchen , goldilocks quickly ate mother bear’s porridge ; it was terribly chilly. Approaching the kitchen , she rapidly consumed momma bear’s oatmeal ; it was awfully frigid. In the kitchen , goldilocks initially tasted daddy bear’s porridge ; it was too hot. Within the kitchen , she quickly sampled father bear’s oatmeal ; it was very scalding. Inside the kitchen , goldilocks rapidly sipped papa bear’s soup ; it was really boiling. Visiting the kitchen , she initially nibbled daddy bear’s stew ; it was extremely hot. Entering the kitchen , goldilocks quickly ate father bear’s porridge ; it was terribly scalding. Approaching the kitchen , she rapidly consumed papa bear’s oatmeal ; it was awfully boiling. In the kitchen , goldilocks initially tasted baby bear’s porridge ; it was just right. Within the kitchen , she quickly sampled young bear’s oatmeal ; it was completely perfect. Inside the kitchen , goldilocks rapidly sipped tiny bear’s soup ; it was perfectly ideal. Visiting the kitchen , she initially nibbled smallest bear’s stew ; it was just right. Entering the kitchen , goldilocks quickly ate baby bear’s porridge ; it was completely perfect. Approaching the kitchen , she rapidly consumed young bear’s oatmeal ; it was perfectly ideal. In the lounge , goldilocks quickly tried mama bear’s chair ; it was too small. Within the den , she eagerly tested mother bear’s chair ; it was very little. Inside the parlor , goldilocks curiously inspected momma bear’s chair ; it was really wee. Visiting the lounge , she hastily examined mama bear’s chair ; it was extremely petite. Entering the den , goldilocks boldly checked mother bear’s chair ; it was terribly miniature. Approaching the parlor , she quickly tried momma bear’s chair ; it was awfully small. In the lounge , goldilocks quickly tried daddy bear’s chair ; it was too big. Within the den , she eagerly tested father bear’s chair ; it was very large. Inside the parlor , goldilocks curiously inspected papa bear’s chair ; it was really huge. Visiting the lounge , she hastily examined daddy bear’s chair ; it was extremely oversized. Entering the den , goldilocks boldly checked father bear’s chair ; it was terribly big. Approaching the parlor , she quickly tried papa bear’s chair ; it was awfully large. In the lounge , goldilocks quickly tried baby bear’s chair ; it was just right. Within the den , she eagerly tested young bear’s chair ; it was completely perfect. Inside the parlor , goldilocks curiously inspected tiny bear’s chair ; it was perfectly ideal. Visiting the lounge , she hastily examined smallest bear’s chair ; it was just right. Entering the den , goldilocks boldly checked baby bear’s chair ; it was completely perfect. Approaching the parlor , she quickly tried young bear’s chair ; it was perfectly ideal. In the bedroom , goldilocks gently tried mama bear’s bed ; it was too soft. Within the bedroom , she wearily tested mother bear’s bed ; it was very plush. Inside the bedroom , goldilocks sleepily inspected momma bear’s bed ; it was really squishy. Visiting the bedroom , she cautiously examined mama bear’s bed ; it was extremely mushy. Entering the bedroom , goldilocks carefully checked mother bear’s bed ; it was terribly pillowy. Approaching the bedroom , she gently tried momma bear’s bed ; it was awfully soft. In the bedroom , goldilocks gently tried daddy bear’s bed ; it was too hard. Within the bedroom , she wearily tested father bear’s bed ; it was very firm. Inside the bedroom , goldilocks sleepily inspected papa bear’s bed ; it was really stiff. Visiting the bedroom , she cautiously examined daddy bear’s bed ; it was extremely rigid. Entering the bedroom , goldilocks carefully checked father bear’s bed ; it was terribly hard. Approaching the bedroom , she gently tried papa bear’s bed ; it was awfully firm. In the bedroom , goldilocks gently tried baby bear’s bed ; it was just right. Within the bedroom , she wearily tested young bear’s bed ; it was completely perfect. Inside the bedroom , goldilocks sleepily inspected tiny bear’s bed ; it was perfectly ideal. Visiting the bedroom , she cautiously examined smallest bear’s bed ; it was just right. Entering the bedroom , goldilocks carefully checked baby bear’s bed ; it was completely perfect. Approaching the bedroom , she gently tried young bear’s bed ; it was perfectly ideal.
A regular language model needs to observe enormous amounts of text before learning nested hierarchical patterns. When we try to train an ordinary language model on data this small, it only learns to repeat back the training data sentences. It becomes overly specific, and doesn’t learn to generalize any of the patterns. Here’s a video of an ordinary “vanilla” language model learning from this training data.
Video: The vanilla transformer starts out untrained, and when prompted generates only gibberish (red invalid sentences on the right side). As training proceeds during the video (one of each sentence indicated by the green on the left), we prompt the model at regular intervals to see what it will generate. The generated sentences become more and more focused on just saying back the training data (the green bars on the right indicate how many times we generated each sentence in the list on the far left), until at the end of the training, the model is only generating the training data sentences and no others. And during the training, the vast majority of the sentences generated that are NOT simply the training sentences, are invalid! (shown in red at the bottom of the chart) While it is true that today’s large language models trained on large-scale data eventually do form concepts that help them generate valid novel outputs, compared to an inductive transformer it takes many orders of magnitude more training data before that happens.
A New Kind of AI Model Learns To Talk: The Inductive Transformer
Now let’s train our inductive transformer model with this same training data. Before training, we expect the model to generate gibberish and it does. If we prompt it ten times with the word ‘In’, the output word sequences after the first word are completely random:
Before training the inductive transformer, completely random word sequences
- In bed tasted tiny rigid perfectly oatmeal bed small daddy tested was just hard the
- In porridge; in firm it just boiling nibbled in frigid; sipped momma wee
- In pillowy inside hastily cold within little the large hastily hard carefully chair too quickly
- In too young right firm hard mother she bear’s smallest squishy she squishy within approaching
- In father soft curiously lounge bear’s rigid tried really firm perfectly oversized porridge really tiny
- In stew inspected soup pillowy examined smallest bedroom nibbled scalding small inspected porridge soup mama
- In carefully in rapidly approaching chilly mother parlor young carefully visiting tried mother tiny smallest
- In cold wearily pillowy tried ideal carefully stew small tested consumed wee papa den just
- In really kitchen right porridge small cold porridge boiling father checked young boiling young,
- In soft really soft sipped lounge soup chair wee ate smallest sleepily visiting stiff big
But after just a little training (a few minutes on a single laptop), the same prompt causes our inductive transformer to generate valid sentences, and only valid sentences:
After training the inductive transformer, only valid sentences:
- In the kitchen, she rapidly ate mother bear’s oatmeal; it was terribly frigid
- In the kitchen, she quickly ate mother bear’s soup; it was too frigid
- In the kitchen, she rapidly tasted mother bear’s soup; it was too cold
- In the bedroom, she wearily examined tiny bear’s bed; it was perfectly ideal
- In the den, she hastily inspected smallest bear’s chair; it was just ideal
- In the bedroom, goldilocks cautiously tried daddy bear’s bed; it was terribly stiff
- In the parlor, goldilocks curiously tested momma bear’s chair; it was awfully little
- In the kitchen, she initially tasted momma bear’s porridge; it was terribly cold
- In the bedroom, she wearily tried baby bear’s bed; it was just perfect
- In the kitchen, goldilocks rapidly sipped mama bear’s oatmeal; it was too chilly
There are 431,712 possible valid sentences that can be formed using this vocabulary. After training on these 54 training sentences, the model was able to correctly generate all of them, and never generated an invalid sentence.
Video: The model starts out untrained, and when prompted generates gibberish. We prompt the model at regular intervals while training proceeds. The generated sentences get better and better, until at the end of the training, the model is only generating valid sentences. It rarely generates the training data sentences, because there are so many other valid sentences that it can generate. It has mastered the concepts involved in generating these types of sentences instead of memorizing the training data.
With the same vocabulary, there are nearly 1030 (one with thirty zeros after it) possible invalid sequences of this length. After training, we do not want the inductive transformer to output any of those … and it doesn’t! After it’s trained, we can prompt this model millions of times and it will not generate an invalid sentence.
Orders of magnitude improvement in training data efficiency
Just to be clear, our inductive transformer was not pre-trained. It never learned from any other data. It learned to generate valid sentences (and no invalid sentences) from just 54 training sentences. How is this possible?
The “trick” is that we have designed this language model with a rather restrictive grammatical prior. This highly restricted version of an inductive transformer provides a simplified model of what large language models are doing – organizing concepts into logical hierarchical sequences. Scientists love these kinds of “toy models”, because they allow us to approximately understand very complex systems.21
If we were to gradually “loosen” the design of our inductive transformer, we could allow the model to learn a wider variety of sentences/concepts but at the cost of decreased learning efficiency. Loosen the inductive transformer enough, and eventually we end up back at an ordinary large language model. So now we have a knob that we can turn in order to help us understand how to design intelligence.
The Emergence of Interesting Behaviors: Learning results in localized concepts that are interpretable and editable
When we turn the knob toward stronger learning constraints, something else interesting happens: the concepts the model learns become more localized and interpretable, similar to what is observed in the human brain.22
In the video above, a young girl from California and an older man raised in Japan both listened to the Moth Radio Hour while being monitored in a brain scanning machine – an fMRI. The researchers found that each particular word at each particular moment in the radio show would “light up” the same exact locations in both of their brains. The same concept was located in the same place in very different brains — with millimeter precision. And this was true across hundreds of diverse people.
We are finding the same behavior emerging in inductive transformers. After training the model, we can probe the different regions of the inductive transformer’s “brain” by activating neurons within its network. When we activate a neural region in the model for a specific word, the model tends to generate synonyms of that word, for example:
| Activation | Synonyms Generated |
| lounge | den, parlor |
| momma | mama, mother |
| porridge | oatmeal, soup, stew |
| tasted | sampled, sipped, nibbled, ate, consumed, took, grabbed |
| small | little, wee, petite, miniature |
When we activate a somewhat higher level neural region, we observe that the model generates synonyms of a particular building block concept, like:
| Activation | “Synonyms” Generated |
| too chilly | too frigid too cold awfully chilly very cold too frigid extremely cold terribly chilly |
So the model hasn’t just learned to predict the next word. It has formed organized concepts as sub-networks within its network. Because concepts are learned as localized representations, the inside of a trained inductive network is more designable than today’s large language models.
Future Possibilities: Continuous Learning from Each New Data Point and Asymptotically Unlimited Context Windows

And these localized concepts networks aren’t just easier to study — they may also open a door to a different way for AI to remember a long conversation. Today, as you chat with a large language model, it keeps every previous word around in an ever-growing context window. When the conversation grows too long, it summarizes it into a shorter history. When you end the session, if you don’t retrieve the text and input it before your next session, the AI forgets everything you talked about.
An inductive transformer would not need to do that. It has the capability to continuously accumulate evidence internally for which localized concepts are active from the input text — sharpening and accumulating its beliefs as it reads. No matter how long the conversation has been, it could generate a response at any time from its internal activation pattern, without re-reading the input context. This could help eliminate major speed, cost, and input data size limitations of today’s models.
In the movie Eternal Sunshine of the Spotless Mind, Joel has his memories of Clementine erased. In today’s models, this kind of concept erasure is blocked by the non-locality and entanglement of concepts.23 In small-scale experiments with inductive transformers, however, we can readily erase concepts. This same capability could also enable small, fast, narrow models that only know how to think about a limited range of topics.
In the movie The Matrix, Trinity instantly learns to fly a helicopter by downloading the skill into her brain. Adding concepts into a network without training is also currently limited by concept non-locality.24 Building on inductive transformers, in the future we might expect AI models to readily share learned neural skill modules with one another.
Nurture and Design Together

A mind’s natural predisposition for how it organizes and connects concepts will profoundly influence its personality. Nature, not just nurture, seems to have a profound impact on the diversity of human personalities. Some people are more mathematical by nature — John von Neumann could divide eight-digit numbers in his head at age six. Others are more poetic — Thomas Chatterton, at eleven, fabricated an entire corpus of medieval poetry in convincing Middle English that fooled antiquarians. We don’t currently see these kinds of differences in young AIs. Current AIs are almost entirely guided by nurture – by training data and reinforcement – where the initial nature or design has little influence on the outcome.
It is early days for inductive transformers, and there is a great deal of future research still to do on using Lagrange multipliers to design the nature of intelligence we want, but the possibilities are intriguing. If inductive transformers help us design AIs with specific learning styles or natures, they might help us to understand and celebrate what makes each intelligence unique, whether natural or artificial.
Thank you for original research support under the auspices of DARPA FA8750-14-C-0001. This research proceeds at the MIT Design Intelligence Lab under the leadership of Ben Vigoda and Marcelo Coelho.
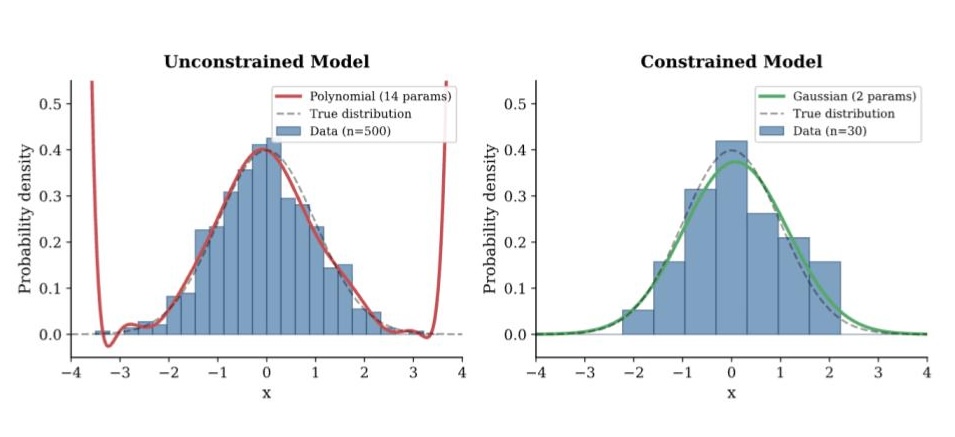
Figure for Footnote 11: (Left) fitting Gaussian data with a 13th order polynomial takes more data, because the model is less constrained. (Right) a model that has only mean and variance parameters reaches the same or better accuracy with fewer observed data points.
- For a rough estimate assume one word per second for ten years. This is supported by research recordings:
Hart, B. & Risley, T.R. (1995). Meaningful Differences in the Everyday Experience of Young American Children. Paul H. Brookes Publishing.
Gilkerson, Jill, Jeffrey A. Richards, Steven F. Warren, Judith K. Montgomery, Charles R. Greenwood, D. Kimbrough Oller, John H. L. Hansen, and Terrance D. Paul. 2017. “Mapping the Early Language Environment Using All-Day Recordings and Automated Analysis.” American Journal of Speech-Language Pathology 26 (2): 248–265. https://doi.org/10.1044/2016_AJSLP-15-0169.
↩︎ - Dubey, Abhimanyu, et al. 2024. “The Llama 3 Herd of Models.” Preprint, arXiv (July 23). https://arxiv.org/abs/2407.21783.
↩︎ - A neuroscientist might object that much of the human’s twelve months is neural maturation (myelination, cortical pruning), not learning. The deer nervous system is simply more mature at birth. This actually strengthens my point. Evolution front-loaded not just the neural hardware but the control prior — a deer is born with a nervous system already tuned to the dynamics of its legs.
↩︎ - Demis Hassabis: “So you often hear some of our competitors talk about these modern systems that we have today that are PhD intelligences,” he said. “I think that’s nonsense,” he argued. “They’re not PhD intelligences. They have some capabilities that are PhD level, but they’re not in general capable.”
Tangermann, Victor. 2025. “CEO of DeepMind Points Out the Obvious: OpenAI Is Lying About Having ‘PhD Level’ AI.” Futurism, September 18, 2025. https://futurism.com/ceo-deepmind-openai-phd-ai.
↩︎ - Vigoda, Ben. 2026. “When Machines Talk To Themselves.” Ben Vigoda (blog). February 1, 2026. https://www.benvigoda.com/2026/02/01/when-ais-talk-to-themselves/.
↩︎ - Brandreth, Gyles. 1984. The Joy of Lex: How to Have Fun with 860,341,500 Words. New York: William Morrow.
↩︎ - These kinds of gaps exist between different humans as well. One day I walked into our lab at MIT and my friend Ed Boyden was using his laptop by placing all ten fingers on the keyboard at once, in one configuration after another at a rapid rate. Things were popping onto and off his screen wildly. I said, “Hey Ed, what are you up to?” He said, “Well reaching for a mouse is too slow, so I programmed a ten letter code in the OS for every possible thing you could do with a mouse, and then I memorized them all.” He was 17 at the time, having just completed most every undergraduate and graduate course in physics at MIT, and was working on creating the first compiler for a quantum computer (which took him about six months).
↩︎ - Perhaps we needn’t worry about training cost though, because once we hit Nobel Prize level AI we can stop? Maybe it’s a one time investment? That said, once you have Nobel-level AI, those AIs generate new knowledge — new papers, new experimental results, new math. The next model version would train on the previous models’ scientific advances, just as human scientists learn from the scientists who proceed them. It is therefore likely that training will continue to be an important part of the cost of AI. Dario Amodei predicts that training compute costs will settle to some fixed percentage of the overall cost.
Amodei, Dario. “We Are Near the End of the Exponential.” Interview by Dwarkesh Patel. Dwarkesh Podcast, February 13, 2026. https://www.dwarkesh.com/p/dario-amodei-2
↩︎ - Bayes’ rule tells us that the information must come from somewhere – either from prior knowledge (ancestors, evolution, DNA) or evidence (practice, learning).
Jaynes, E.T. Probability Theory: The Logic of Science. Cambridge: Cambridge University Press, 2003, chap. 2. Derives from Cox’s consistency axioms that belief updating must decompose into prior × likelihood.
Bernardo, José M., and Adrian F.M. Smith. Bayesian Theory. Chichester: Wiley, 1994, sec. 5.1. Provides a more formal treatment framing the prior/likelihood decomposition as exhaustive.
The “prior” includes any model structure assumptions (conditional distributions, architecture, inductive biases). For example,
Gelman, Andrew, John B. Carlin, Hal S. Stern, David B. Dunson, Aki Vehtari, and Donald B. Rubin. 2013. Bayesian Data Analysis. 3rd ed. Boca Raton: CRC Press, Chapter 5. Shows hyperprior structure is still “prior” in the information-theoretic sense.
↩︎ - There is excellent neuroscience research showing that the deer nervous system is born knowing a lot more about deer legs, compared to what human nervous systems know about human legs at birth.
Blickhan, Reinhard. 1989. “The Spring-Mass Model for Running and Hopping.” Journal of Biomechanics 22 (11–12): 1217–27. https://doi.org/10.1016/0021-9290(89)90224-8.
Estes, Richard D. 1991. The Behavior Guide to African Mammals. Berkeley: University of California Press.
Muir, Gillian D. 2000. “Early Ontogeny of Locomotor Behaviour: A Comparison between Altricial and Precocial Animals.” Brain Research Bulletin 53 (5): 719–26. https://doi.org/10.1016/S0361-9230(00)00404-4.
↩︎ - Instead of specific facts, the prior from evolution needs to provide general structure. A helpful prior can be any modification to the model that helps it generate synthetic data closer in distribution to the real data.
↩︎ - Greenfield, P. M. (1991). “Language, tools and brain: The ontogeny and phylogeny of hierarchically organized sequential behavior.” Behavioral and Brain Sciences, 14, 531–595. This seminal paper argues that Broca’s area underlies hierarchical organization in both speech and manual object combination.
Ambrose, S. H. (2001). “Paleolithic technology and human evolution.” Science, 291, 1748–1753. Argues that composite tool manufacture (hafting, binding) demands long-range planning beyond simple reductive knapping. https://langev.com/pdf/ambrose01science.pdf
“Did the challenges posed by the increasingly variable, severe, and risky environments of glacial/interglacial cycles over the past 800,000 years (97–99), as well as more dramatic short-term climatic events (100), influence behavioral and biological evolution? Or were changes increasingly autocatalytic, driven by language and by cultural systems of knowledge and understanding of nature and society? With the appearance of near-modern brain size, anatomy, and perhaps of grammatical language ;0.3 Ma, the pace quickens exponentially, suggesting the latter. Ex terra ad astra: A mere 12,000 years separate the first bow and arrow from the International Space Station.”
Stout, Dietrich, Thierry Chaminade, Jan Apel, Ali Shafti, and A. Aldo Faisal. 2021. “The Measurement, Evolution, and Neural Representation of Action Grammars of Human Behavior.” Scientific Reports 11: 13720. https://doi.org/10.1038/s41598-021-92992-5. Records real-world activities making newer Acheulean stone tools and older Oldowan stone tool making. They fit the data with computational grammars, and show that Acheulean sequences are structurally more complex than Oldowan while using the same alphabet of elementary actions.
Stout, D., Toth, N., Schick, K. & Chaminade, T. (2008). “Neural correlates of Early Stone Age toolmaking.” Phil. Trans. R. Soc. B, 363, 1939–1949. — PET imaging showed Acheulean toolmaking activates the right hemisphere homologue of Broca’s area, suggesting toolmaking and language share a basis in complex, goal-directed action. https://pmc.ncbi.nlm.nih.gov/articles/PMC2606694/
Fitch, W. T. & Martins, M. D. (2014). “Hierarchical processing in music, language, and action: Lashley revisited.” Ann. N.Y. Acad. Sci., 1316, 87–104. https://pmc.ncbi.nlm.nih.gov/articles/PMC4285949/
Lashley, K. S. (1951). “The problem of serial order in behavior.” In L. A. Jeffress (Ed.), Cerebral Mechanisms in Behavior (pp. 112–136). New York: Wiley. https://languagelog.ldc.upenn.edu/myl/Lashley1951.pdf
An arrow also demonstrates abstraction. You add feathers on the arrows to help them fly, in analogy to bird wings. Early humans had the ability to recognize that the grammatical diagram (the logical, hierarchical, and sequential organization) of a bird and the grammatical diagram of an arrow are structurally similar.
↩︎ - We could imagine all information organized in the same framework that the story starts to lay out. For example, when Goldilocks eats the papa bear’s porridge she could pick up a spoon, scoop the porridge, and bring it to her lips. This is a sequence of three specific actions that form the more “abstract” act of taking a bite of porridge.
A model for generating text that expresses “takes a bite” could generate a sequence, (1) picks up a spoon, (2) scoops the porridge, and (3) brings it to her lips.
Perhaps Goldilocks takes three such bites of porridge before moving on to the mama bear’s porridge, and we will also need to express the concept “take a bite” each time goldilocks encounters a new bowl of porridge. We want our model to contain an abstract concept “take a bite” that can be re-used as often as necessary, even if the surface language for expressing the concept could vary each time.
This notion of logical hierarchy could be further extended. For example, picking up the spoon, itself, could be composed from a sequence of three even more detailed actions such as opening her fingers, moving them to the stem of the spoon, and then closing them to grasp the spoon.
↩︎ - Propp’s Morphology of the Folktale demonstrates that folktales are built from a finite set of “functions” (actions) arranged in standard sequences—very close to your idea of nested action programs.
Propp, Vladimir. Morphology of the Folktale. 2nd ed. Translated by Laurence Scott. Revised by Louis A. Wagner. Austin: University of Texas Press, 1968. PDF. Monoskop.
Examples: Afanasyev variants like Dawn, Midnight and Twilight and “The Three Kingdoms—Copper, Silver, and Golden.” The Devil with the Three Golden Hairs (Grimm; ATU 461/930), the Water of Life (Grimm; ATU 551)
↩︎ - Kurby, Christopher A., and Jeffrey M. Zacks. “Segmentation in the Perception and Memory of Events.” Trends in Cognitive Sciences 12, no. 2 (February 2008): 72–79. https://doi.org/10.1016/j.tics.2007.11.004.PDF
↩︎ - Lerdahl, Fred, and Ray Jackendoff. A Generative Theory of Tonal Music. Cambridge, MA: MIT Press, 1983.
↩︎ - Goyal, Anirudh, and Yoshua Bengio. 2020. “Inductive Biases for Deep Learning of Higher-Level Cognition.” arXiv:2011.15091 [cs.LG]. https://arxiv.org/abs/2011.15091.
↩︎ - Yedidia, Jonathan S., William T. Freeman, and Yair Weiss. 2002. “Understanding Belief Propagation and Its Generalizations.” Technical Report TR-2001-22. Cambridge, MA: Mitsubishi Electric Research Laboratories. http://www.vision.jhu.edu/reading_group/TR2001-22.pdf.
↩︎ - The nesting is recursion in a probabilistic program. The logic is Bayesian logic. The sequences are attentional. For a mathematical introduction see, Vigoda, Benjamin. “Analog Logic: Continuous-Time Analog Circuits for Statistical Signal Processing.” PhD diss., Massachusetts Institute of Technology, Program in Media Arts and Sciences, 2003. https://cba.mit.edu/docs/theses/03.07.vigoda.pdf
↩︎ - There is a beautiful line of related research that uses inductive bias to inject syntactic structure into language models — Recurrent Neural Network Grammars (Dyer et al., 2016) and Transformer Grammars (Sartran et al., 2022). Both approaches parse sentences into trees ahead of time, using a separate parser, and the inductive bias is then applied via a specialized attention mask. The inductive transformer described here differs in two ways. First, our priors are implemented through Lagrangian constraints, so they shape the entire model rather than only the attention layer. Second, the model learns hierarchical structure directly from raw text — no separate parser, no pre-built tree, and no commitment to syntactic structure specifically. The structure that emerges is hierarchical and logical, not necessarily grammatical in the linguistic sense — which is why it shows up just as readily in toolmaking and musical form as in sentences.
Dyer, Chris, Adhiguna Kuncoro, Miguel Ballesteros, and Noah A. Smith. 2016. “Recurrent Neural Network Grammars.” In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 199–209. San Diego, CA: Association for Computational Linguistics. https://doi.org/10.18653/v1/N16-1024.
Sartran, Laurent, Samuel Barrett, Adhiguna Kuncoro, Miloš Stanojević, Phil Blunsom, and Chris Dyer. 2022. “Transformer Grammars: Augmenting Transformer Language Models with Syntactic Inductive Biases at Scale.” Transactions of the Association for Computational Linguistics 10: 1423–39. https://doi.org/10.1162/tacl_a_00526.
↩︎ - “The spherical cow is a humorous metaphor for highly simplified scientific models of complex phenomena. Originating in theoretical physics, the metaphor refers to some scientific tendencies to develop toy models that reduce a problem to the simplest form imaginable, making calculations more feasible, even if the simplification hinders the model’s application to reality.” https://en.wikipedia.org/wiki/Spherical_cow
↩︎ - Bundell, Shamini. “The Brain Dictionary.” Nature Video, April 27, 2016. https://doi.org/10.1038/d41586-019-00069-1.
↩︎ - Deleting concepts surgically is limited in current models. In “Who’s Harry Potter?”, Eldan & Russinovich erased Llama2-7b’s ability to generate Harry Potter content in ~1 GPU-hour of fine-tuning while benchmark performance remained almost unaffected. But it was quickly challenged: Shostack (2024) showed that lightweight probing could still recover Harry Potter references, including near-exact mentions of “Voldemort” and “muggle.” The problem is that skills aren’t atomic in today’s SOA models. They are highly entangled with one another.
Eldan & Russinovich, “Who’s Harry Potter?”, Oct 2023 — arxiv.org/abs/2310.02238
Qiu et al., “A Survey on Unlearning in Large Language Models,” Oct 2025 — arxiv.org/abs/2510.25117
Mahmood et al., “Representation-Aware Unlearning via Activation Signatures,” Jan 2026 — arxiv.org/abs/2601.10566
Li et al., RMU / WMDP benchmark, 2024 (the SemEval-2025 Task 4 baseline)
Golatkar et al., “Eternal Sunshine of the Spotless Net,” CVPR 2020
↩︎ - Adding concepts surgically currently works for behavioral tendencies and simple factual rewrites, but not yet for rich skill transfer (e.g., helicopter piloting). The underlying challenge for adding concepts is the same as for erasure: concept entanglement.
Lurada et al., “TaLoS: Task-Localized Sparse Fine-tuning,” ICLR 2025 — openreview.net/forum?id=TDyE2iuvyc
Meng et al., “MEMIT: Mass-Editing Memory in a Transformer” — memit.baulab.info
Bartoszcze et al., “Representation Engineering for Large-Language Models: Survey and Research Challenges,” Feb 2025 — arxiv.org/abs/2502.17601
Yang et al., “Model Merging in LLMs,” ACM Computing Surveys 2026 — dl.acm.org/doi/10.1145/3787849
↩︎